Looking at the Data🔗
The data page can give you a lot of information about each run of your program. To access this page, simply click "Data" from the homepage, or click "Data" in similar option menus on any of the other pages.
What the Data Page Shows🔗
The data page shows each and every run or preview that has ever been done on your program, whether the preview or run was completed fully or only partially completed. This page has several different columns, which we'll go over one by one.
User🔗
If the user that completed that preview or run was logged into GuidedTrack, you will see here their unique user ID. If they do not have an account with GuidedTrack, or were logged out while completing their preview or run, then this field will be blank. Take a look at the section on logging in if you want to require your users to log in.
Time Started🔗
This is the time in which a user began a preview or run.
Total Time Spent🔗
This column lists, in minutes, the amount of time a user spent completing your run. If the user completed your run in multiple sittings, or if they left the program open for an extended period of time (perhaps while doing other things), then this time may look very large.
Finished🔗
There will be a small checkmark here if the user finished your program, that is, if they got to a screen where they could not possibly go forward.
Visible Points Counts🔗
If your program awards generic points (the type that users can see in the upper corner of their screen, i.e. points without a codeword), then the total number of points they got will be displayed here. Next to their total points, and in parentheses, will be the total percentage of points the user received out of the maximum possible number of points. So, if your program awarded up to 10 points and one user got 8 points, you would see "8 (80%)" for that user's run.
If your program awards special points (the type that users cannot see in the upper corner of their screen; i.e., points with a codeword), then you will also see the total number of points the user got for that point type and the percentage of that point type's total. So, if it were possible to get up to 40 "gnarly" points in your program and a user got 20 gnarly points, you would see "20 (50%)" under a column called "Points (gnarly)". If you're not sure what we mean by special points, review the section on points.
Answers🔗
In the column that says the word "Answers" after each run or preview, you can click on any of the "Answers" to see the particular questions asked of each user during their preview or run and the exact answer that they gave.
By clicking on any of the questions on an "Answers" page, you can also see other answers that all other users gave for that question. You can also see all the answers given for a particular question by going to the "Questions" tab, which we'll describe in a bit.
Details🔗
This is the technical stuff, and is not particularly useful for the majority of people; feel free to skip over this whole section! Clicking "Details" for any user's run or preview will show you a detailed play-by-play of exactly what that user clicked on, saw, and typed, all the keywords they came in contact with, as well as the exact time in which these things occurred and in what sequence. The details page is not for the faint of heart! Here's an overview of what the details page contains:
Time: The time that the event occurred at.
Category: There are a few different categories that could be here. Basically, a category will tell you the category of the event that occurred (e.g. "answer" if the answer just gave an answer; "start_run" if it's the beginning of the run).
Node ID: Nodes are unique identifiers, made up of a 7-character string of numbers and letters. Each line of text, keyword, question and answer pair, etc., will have a unique identifier. You don't really need to know what it is, but it occasionally comes in handy.
Type: Type is similar to "Category," but it's more specific. The type will tell you the type of event that occurred (e.g. "text" for lines of text, "button" if there was a button, "question_multiple_choice" if there was a multiple choice question).
Text: Text will show you any text that was written at that point in the program: on a button, in a question, or in other areas where text is shown.
Value: This column is most useful for seeing the answers that a user gave if they answered a question at that particular point. This column may also include nodes, which can be safely ignored. Answers can also be obtained through much easier ways, as described earlier.
Sequence: If you used any *randomize keywords in your program, then the sequence of what the user saw will be shown here. The sequence will be provided in nodes, unless you gave each possible randomization a unique *name, in which case you will see the codenames in the sequence in which they occurred. See the section on naming randomizations for more information.
URL: If you provided a URL to the user at this point in the program, then you will see the link to that URL here.
Sequence #: This column will be in numerical order. It tells you when this event occurred in the sequence of all events.
Test or Data🔗
This column will show you whether this row represents a preview or an actual run. If the icon here says "test", then the information will be shown in a slightly dimmed font and the data provided here will not be included in a downloaded CSV of the data.
If the icon here says "data", then the information is in normal font color and the data provided will be included in a downloaded CSV of the data.
You can toggle these icons back and forth between "test" and "data." Allow the icon to say "data" if the row represents a legitimate run of your program and/or you are interested in analyzing the data of that run later on. Make the icon say "test" if the row represents a preview run of your program and/or you do not want that data to be a part of your CSV.
Understanding and Looking at the Questions Tab🔗
The "Questions" tab will show you all of the questions asked in your program. In a small blue box, you can also see how many times that question was answered during runs of your program.
Your program may also have a column that says "Versions." The most recent version of your program will be listed first. If you deleted any questions or significantly modified any questions, prior versions of questions will be listed as well, beneath earlier version numbers.
You can click on any of the questions to see the actual answers that users gave. You'll come to a page called "Listing answer," which will also give the following:
Question🔗
The question that was asked.
A Chart🔗
The chart will show you a bar chart of the number of times an answer was given and the percentage that each answer was given. This chart will show for all types of questions, including multiple choice, text, and paragraph. However, if there are more than 15 unique answers (which may be especially likely in a text or paragraph question) then the chart will not appear.
Answers🔗
The total number of times this question was answered.
Numerical🔗
The total number of times this question was answered numerically (i.e., someone wrote 7, 3.2, or another number as their answer).
Average🔗
The average of all numerical responses.
Time🔗
The time at which the answer was given.
Value🔗
The actual answer that was given.
Generating and Understanding a CSV of Your Data🔗
If you'd like to generate a CSV of your data that you can download onto your computer, simply click the large blue button that says "Generate CSV." You will have to wait a few moments while the program crunches your data. Once it's finished, a green "Download CSV" will be displayed and you can click on it to download or open your CSV. Remember, this CSV will only show you data that was generated from actual runs of your program, not quick previews of your program.
Your CSV will contain a lot of information and may at first look a bit overwhelming. We'll explain each column in detail.
Run🔗
This is a unique number provided to that individual run, distinguishing it from all other runs in all other GuidedTrack programs.
Program Version🔗
This is the version of your program that the run occurred on.
User🔗
If the user that completed that preview or run was logged into GuidedTrack, you will see here their unique user ID. If they do not have an account with GuidedTrack, or were logged out while completing their preview or run, then this field will be blank. Take a look at the section on logging in if you want to require your users to log in.
Time Started🔗
This is the time in which a user began a run.
Time Finished🔗
This is the time in which a user completed a run.
Time Spent🔗
This column lists, in minutes, the amount of time a user spent completing your run. If the user completed your run in multiple sittings, or if they left the program open for an extended period of time (perhaps while doing other things), then this time may look very large.
Position🔗
This column will show a unique code (or "node") that can tell you how far along a user has gotten in their run, before quitting, voluntarily leaving, or completing the run. The code represents the text or keyword that was at the top of the last visited screen.
Points Totals🔗
If your program awarded generic points (the type that users can see in the upper corner of their screen, i.e., points without a codeword), then the total number of points they got will be displayed here.
Points Percentages🔗
If your program awarded generic points, this column will have the total percentage of points the user received out of the maximum possible number of points. So, if your program awarded up to 10 points and one user got 8 points, you would see 80% for that user's run.
Additional Columns🔗
You will also see additional columns for these types of things (if you've added them to your program).
Special points: If your program awards special points (the type that users cannot see in the upper corner of their screen; i.e., points with a codeword), then you will also see the total number of points the user got for that point type and the percentage of that point type's total. So, if it were possible to get up to 40 "gnarly" points in your program and a user got 20 gnarly points, you would see "20" under a column called "Points (gnarly)" and "50%" under a column called "Points % (gnarly)".
Randomize: If you used this keyword, you'll see the unique identifier of that randomization, with the single or sequence of randomizations that occurred for that user. Be sure to visit the naming randomizations section to make sure the data here is easily readable.
Variables: If you've added any variables, you'll see the codename of the variable in the column heading and their final ending values below. For *set variables, these will appear as "TRUE" if the user tripped the *set keyword, or the cells will be blank if the user did not trip the *set variable.
Questions: If your data includes questions, you'll see each question in the column, with the answers beneath it. If the user answered the same question multiple times (either by pressing a back button or via a *goto keyword), then each of their answers will be separated by a pipe (|).
How can you deal with the pipes (|) on your CSV file (which can occur if a participant responds more than once to the same question)?🔗
There are various ways that a user may end up answering a question multiple times. For instance, if your program contains looping, the user might literally get to the same question more than once. It can also happen if they use back buttons to change their answer. Furthermore, it may happen if they refresh the page or even if a server error occurs.
Let's look at this program, which shows an example of it happening due to looping the user back to the same question over and over:
*label: askQuestion
*question: How many books have you read this year so far?
*save: booksReadSoFar
*type: number
That's great!
*button: Enter new number of books
*goto: askQuestion
As you can see, this program keeps on asking the same question over and over. When you look at the CSV file, this is what you find:

The column in the file that shows the answer to the question displays ALL the answers a user entered in that run of the program, in the same order they were entered and separated by a pipe (so, the value at the right is the last value the user entered). This is valuable information, because it allows you to see how many times the user answered a question, to track their progress, etc. However, if you need to easily calculate the total number of books your users have read, you need to have the last value each user entered in a separate column.
If you are designing your program and notice this is going to be the case before you share it with the users that will generate the data, you can save the value of the answer to a variable, as we have done in the sample program. As you can see, the value of the variable booksReadSoFar always keeps the last value a user entered.
If you are analyzing your data and you did not save the value to a variable, you can use this Python script that will generate a new CSV file that removes all previous answers to each question. This is how the output file looks like:

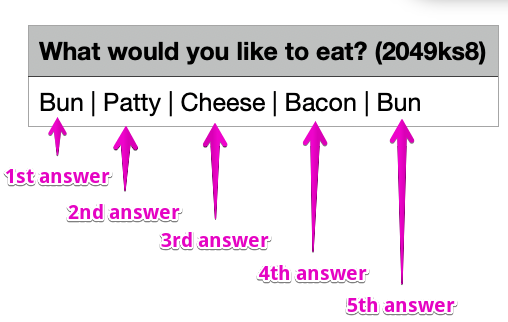
Another way that this might be happening is when you enable the GuidedTrack Back Button, thus allowing users to go back to the previous question and change their answers. Notice in the GIF below that the user went back to the previous question and changed their answer from Bun to Patty to Cheese to Bacon and finally to Bun before submitting the survey.
The answers appear in the CSV in the same order as the user gave them. The first answer is leftmost, then comes the separator (“|”), followed by the second answer and so on until the user submits the survey.
Next: Account dashboard